Опыт написания поисковой системы
Автор: mike.nov.ru
В настоящее время в мире функционируют более 10 крупных поисковых
систем, но вот небольших, корпоративных, легко устанавливаемых на
сервер, не так уж и много. В этой статье я попытаюсь рассказать о
том, как пробовал писать такую систему, с какими трудностями я
столкнулся, и какие структуры я использовал.
Я не считаю, что мой вариант супер оптимальный, скорее наоборот.
Я буду очень рад, если вы напишите все, что думаете по поводу этой
статьи, предложите свои варианты, и поможете мне написать гораздо
более оптимальную поисковую систему.
Оглавление
1. Введение.
Поисковая система состоит из 3 мощных компьютеров, каждый из
которых выполняет свои задачи:
- WWW-сервер. Отвечает за взаимодействие поисковой системы с
пользователем. Предоставляет удобный и наглядный интерфейс для
задания запросов.
- Поисковая машина. Это, как правило, очень мощный компьютер,
который обрабатывает базу индексов в соответствии с полученным
запросом.
- Поисковый робот. Компьютер, оснащённый специальной программой,
которая непрерывно просматривает весь Интернет, индексируя все все
встречающиеся Web-страницы, и обновляя базу индексов.

Так устроены все поисковые системы, их различие состоит по сути
лишь в вычислительной мощности перечисленных элементов и их
программном обеспечении.
Рассмотрим теперь более подробно, как происходит поиск информации
с помощью поисковой системы.
Пользователь, желая найти необходимую информацию с помощью
браузера Интернет соединяется с WWW-сервером поисковой системы. На
основной странице, как правило, содержится поле, в котором
набирается запрос, например, одно или несколько ключевых слов, а
также специальных слов и символов. После того как запрос
подготовлен, пользователю остаётся отдать команду на поиск
Web-страниц, которые соответствовали бы запросу. Как правило, для
этого есть кнопка Search, Find, Submit и т.д. Сформированный запрос
передаётся на поисковую машину.
Поисковая машина, получив запрос от WWW-сервера, просматривает
собственную базу индексов, т.е. базу данных обо всех зафиксированных
поисковой системой Web-страниц. В этой базе для каждой Web-страницы,
которую просмотрел поисковый робот, имеется индекс - список
встречающихся на этой странице значащих слов (исключая предлоги,
союзы и междометия). После того как найдены адреса всех Web-страниц,
отвечающих запросу, создаётся список адресов, который и
предъявляется пользователю в окне браузера. Если быть более точным,
то в большинстве случаев на WWW-сервере поисковой системы создаётся
Web-страница, состоящая из списка адресов, удовлетворяющих запросу.
Это можно заметить по строке адреса в браузере. Список содержит
аннотации и активные ссылки, по которым можно переключиться на
интересующие вас серверы Интернета.
Наконец, за всем этим стоит непрерывная и кропотливая
деятельность поискового робота, который днём и ночью просматривает
все доступные Web-сайты и составляет их индексы, обновляя
собственную базу индексов, которая используется, как это было
описано выше, для составления ответов на запросы пользователя.
Многие поисковые системы предоставляют возможность занесения
собственного адреса в список индексируемых ресурсов
Постановка задачи
Основная задача нашей поисковой системы - простота установки,
минимальные системные требования и высокая скорость работы.
Большинство существующих поисковых систем требуют один или
несколько выделенных серверов, я же пытался написать поисковый
механизм не требующий не только выделенного сервера, но не требующий
даже дополнительного ПО, такого как SQL сервера.
Весь индекс поисковой системы хранится в файлах, имеющих сложную
древовидную структуру.
Программа состоит из двух основных частей - поисковый работ
(индексатор) и механизм поиска по индексу.
Рассмотрим более подробно функции каждой части:
Индексатор:
Индексатор должен выполнять следующие действия:
- Поиск файлов заданного типа на диске. (обычно HTML, HTM,
STHML,SHTM)
- Выделение из каждого файла заголовка (в HTML документах
заголовок находится между тегами <TITLE> и </TITLE>)
- Выделение информации из документов, фильтрация скриптов (теги
<SCRIPT>:</SCRIPT>), таблиц стилей
(<STYLE>..</STYLE>), комментариев (<!-- -->) и
других служебных лексем.
- Сохранение информации о документах в специальном файле,
присвоение документу уникального номера.
- Сохранение информации о каждом слове, и номере документа в
индексе.
Механизм поиска по индексу.
- Механизм должен искать в индексном файле каждое слово из
поискового запроса.
- Должен сортировать результаты поиска по релевантности и
соответствию.
- В первую очередь выводятся результаты строго соответствующие
запросу (если каждое слово запроса существует в найденном
документе).
- Результаты сортируются по релевантности - количеству слов
запроса, встреченных в найденном документе.
- Форматирование результатов поиска и разбивка их на страницы.
Форматы файлов данных
Файл, содержащий список файлов (files)
- Содержит подробную информацию о индексированных файлах
- Состоит из последовательно расположенных записей, имеющих
следующий формат.
Таблица 1 - информация о документе.
| Смещение |
Размер |
Описание |
| 0 |
512 |
Информация о расположении файла -
путь.Например:
Windows: C:\TEMP\my_site\
Unix: /home/user/htdocs/ |
| 512 |
256 |
Заголовок документа |
| 768 |
256 |
Описание документа (произвольная фраза из
документа) |
Индексный файл (index):
- Содержит информацию о словах встречающихся в документах, и
принадлежность слова документу.
- Имеет древовидную структуру, состоящую из двух типов записей.
Всегда начинается с записи идентификации слова.
Таблица 2 - запись идентификации слова.
| Смещение |
Размер |
Описание |
| 0 |
4 |
Значение хеш функции слова |
| 4 |
32 |
Слово (заглавными буквами) |
| 36 |
4 |
Указатель на следующую структуру идентификации слова,
значение хеш функции которой меньше текущего. Если ноль, то
конец ветви дерева. |
| 40 |
4 |
Указатель на следующую структуру идентификации слова,
значение хеш функции которой больше текущего. Если ноль, то
конец ветви дерева. |
| 44 |
4 |
Указатель на структуру идентификации
документа. |
Таблица 3 - запись идентификации документа.
| Смещение |
Размер |
Описание |
| 0 |
4 |
Номер документа (N). Информация о документе может быть
получен из файла files по смещению (N*1024) (см. таблицу
1) |
| 4 |
4 |
Сколько встречается слово в этом документе |
| 8 |
4 |
Указатель на следующую структуру идентификации документа.
Если ноль, то документов содержащих поисковое слово больше
нет. |
| 12 |
4 |
Зарезервировано |
Алгоритм поиска по индексу.
Допустим мы ищем слово МИР, значение хеш функции - 173h
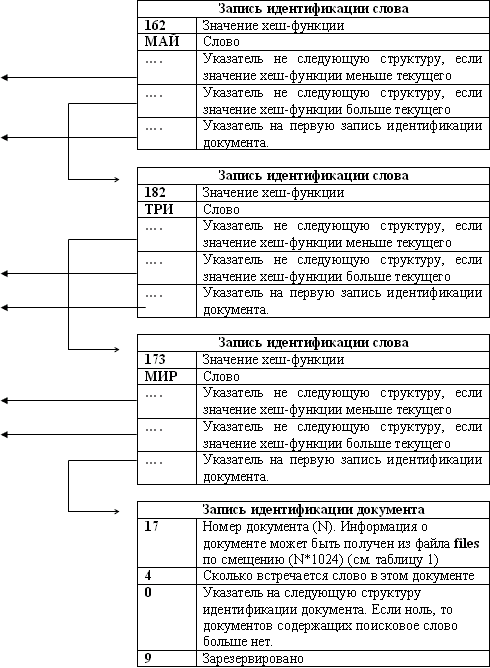
Таким образом, мы установили, что слово мир, встречается 4 раза в
документе №17. Информацию о документе мы можем получить из файла
files по смещению 17*1024=17408
Плюсы и минусы алгоритма.
Достоинствами программы являются:
- 1. Низкие системные требования
- 1.1 Индексатор:
- 1.1.1 Процессор: 486dx и выше
- 1.1.2 Память: 8Mb
- 1.1.3 Место на жестком диске в зависимости от размеров
индексируемых данных
- 1.1.4 ОС: Windows95/98/ME/2000, FreeBSD Unix 4.3, S.U.S.E.
Linux 7.1
- 1.2 Система поиска оп индексу
- 1.2.1 ПО: PHP 3.0 и выше, к аппаратной части не привязан.
- 2. Высокая скорость поиска по индексу.
Недостатками программы являются:
- Невозможность работы с протоколами HTTP и FTP
- Невозможность обновления индексных файлов (необходимо все
индексировать заново)
- Невысокая скорость индексатора (на 2xP-III, SCSI, S.U.S.E.
Linux скорость составила ~230 Kb/сек)
Использование программы.
Работа с индексатором:
Работа с индексатором (для Unix и Linux - indexer, для Windows -
indexer.exe) производится посредством ключей командной строки:
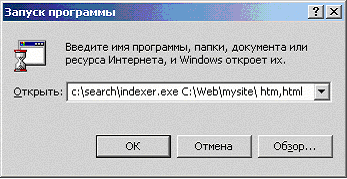
Для ОС Windows
| C:\> indexer.exe путь расширения |
Где:
- путь - каталог с HTML документами.
- расширения - расширения обрабатываемых файлов через запятую.
Пример:
Для ОС семейства Unix
| bash# /home/user/indexer путь расширения |
Где:
- путь - каталог с HTML документами.
- расширения - расширения обрабатываемых файлов через запятую.
Пример:
| bash# /home/user/indexer ./htdocs/
html,html,shtm,shtml |
Работа с системой поиска по индексу:
Для установки системы поиска по индексу необходимо выполнит
следующие действия.
- Скопировать файлы search.php, top.php и config.php в WWW
каталог сервера поддерживающего PHP версии 3.0 и выше.
- Изменить файл config.php следующим образом:
<?php
$idxname="index"; // Имя индексного файла
$lstname="files"; // Имя файла со списком документов
$debug=0; // см. Ниже
$rec_in_page=10; // Количество результатов на странице
$opt_path="C:/web/mysite/"; // Путь на локальном диске (*)
$opt_url="http://www.codenet.ru/"; // URL (*)
?>
Переменная debug используется в процессе установки поисковой
системы, при debug=1 в результатах поиска выводится время
потраченное на него.
(*) Переменная $opt_path содержит путь индексируемого каталога на
локальном диске, причем слеши должны быть "/". А переменная $opt_url
содержит путь в "WWW" к этому же каталогу.
Скачать версию для Windows можно здесь.

